DeepSeek
Open-weight AI chatbot and API with 1M-token context and usage-based pricing
FREEMIUM Verified JUN 11, 2026
Alibaba's open-weight LLM family plus a free multimodal chat assistant and token-based API
Qwen is Alibaba's family of large language models — open-weight releases under the Apache 2.0 license, including the 235B-parameter Qwen3 mixture-of-experts model — paired with a free multimodal chat assistant and a token-based API. Qwen Chat is free to use; the API runs from about $0.05 per million input tokens via Alibaba Cloud. Best for developers who want capable open models to self-host or cheap, OpenAI-compatible API access.
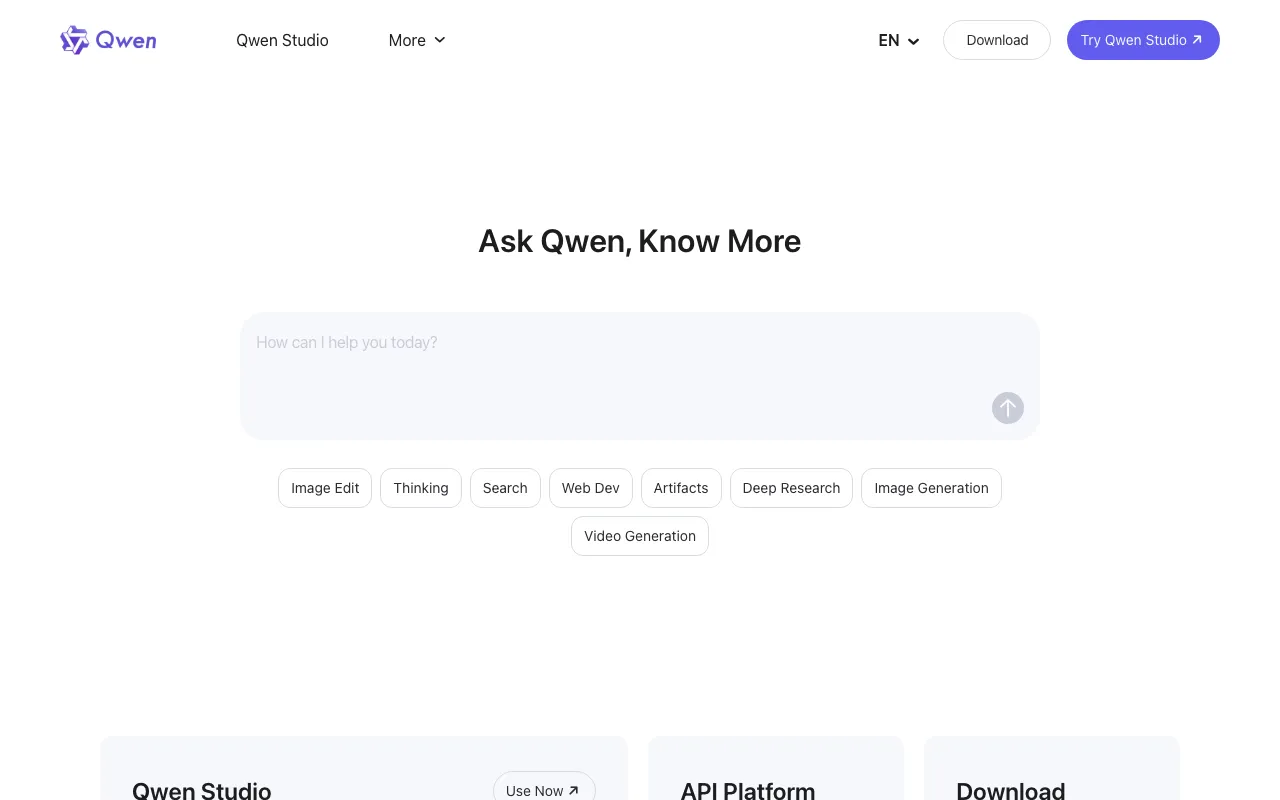
Qwen is Alibaba’s family of large language models, and it shows up in three forms. First, there is Qwen Chat — a free multimodal assistant on the web and mobile that handles text, understands images and video, and generates images, with very large context windows on its top models. Second, the models are released as open weights under the permissive Apache 2.0 license, so anyone can download and self-host them at no license cost. The lineup spans from tiny models that run on modest hardware up to the Qwen3 mixture-of-experts flagship, which has 235 billion total parameters (with 22 billion active per token).
Third, for teams that would rather not run their own infrastructure, Qwen is available as a token-based API through Alibaba Cloud Model Studio, with OpenAI-compatible endpoints. Pricing is competitive: the lightweight Qwen-Flash starts around $0.05 per million input tokens, while the flagship Qwen3-Max starts near $1.20 per million, with discounts for batch processing and context caching. New accounts get a 90-day allowance of one million free tokens per model. The main caveats are that API pricing is tiered by context length and reasoning mode, and that prices and availability differ by region.
Qwen appeals to people who value openness, low cost, and multilingual capability. The free chat is fine for everyday use, but Qwen’s real distinction is for builders who want to own their stack or keep API spend low.
Starting price: $0 · Free tier: yes · Model: open-source
Price history tracked from June 2026
| Plan | Price | Includes |
|---|---|---|
| Qwen Chat | Free | Free multimodal web and mobile chat assistant · Text, image, and video understanding plus image generation · Context window up to roughly 1M tokens · No paywall or login wall for core use |
| Open weights | Free | Apache 2.0 licensed model weights · Qwen3 series, including the 235B-parameter mixture-of-experts model · Self-host via Hugging Face, Ollama, or vLLM · Full size ladder down to small edge models |
| API (Model Studio) | $0.05/M | Qwen-Flash from $0.05 per million input tokens · Qwen3-Max from $1.20 per million input tokens · OpenAI-compatible endpoints via Alibaba Cloud · 1M free tokens per model for 90 days on new accounts |
| Pros | Cons |
|---|---|
| Genuinely free, capable, multimodal chat with no paywall for core use | API pricing is tiered by context-length band and split into thinking/non-thinking rates, so cost is easy to underestimate |
| Truly open weights under Apache 2.0 — self-host with no license cost | Ongoing API use is paid — the free quota is a 90-day, 1M-token-per-model trial for new accounts |
| Very cheap API at the low end (Flash from $0.05 per million input tokens) and competitive at the top | Pricing and availability vary by deployment region (international vs mainland China) |
| Broad lineup from tiny edge models up to a 235B mixture-of-experts flagship | Self-hosting the large mixture-of-experts models requires serious GPU resources |
Open-weight AI chatbot and API with 1M-token context and usage-based pricing
Mistral's multimodal AI assistant — chat, web search, code execution, and image generation from a European frontier lab
Conversational AI assistant by OpenAI with multimodal reasoning, voice, and agent capabilities
Google's multimodal AI assistant with real-time Search access and deep Workspace integration
Anthropic's AI assistant built for long-context analysis, coding, and safe reasoning
Yes, in two ways. The Qwen Chat assistant is free to use on the web and mobile, and the model weights are released under the Apache 2.0 license, so you can download and self-host them at no license cost. The paid part is the hosted API, billed per token.
The Qwen3 series is current, including the Qwen3-Max flagship and a 235B-parameter mixture-of-experts model (with 22B active parameters), alongside smaller dense models. The earlier Qwen2.5 generation is still widely used for self-hosting.
It is token-based via Alibaba Cloud Model Studio. The cheapest model, Qwen-Flash, starts around $0.05 per million input tokens, while the flagship Qwen3-Max starts around $1.20 per million input tokens. New accounts get 1 million free tokens per model for 90 days.
Yes. The open-weight Qwen models are Apache 2.0 licensed and can be run via Hugging Face, Ollama, vLLM, and similar tooling. Smaller models run on modest hardware, while the large mixture-of-experts models need substantial GPU resources.
Yes. Qwen Chat handles text plus image and video understanding and can generate images, and several Qwen models support vision. Top models also offer large context windows (up to roughly 1 million tokens) and dedicated thinking modes for reasoning.
Qwen, DeepSeek, and Llama are all open-weight model families. Qwen stands out for its broad size ladder, strong multilingual support, and a free hosted chat assistant. As with any model, the right choice depends on your task, language needs, and hosting constraints.